
Hotelführung im Familienbetrieb

Logenplatz mit Zugspitzblick und ganz viel Freiraum

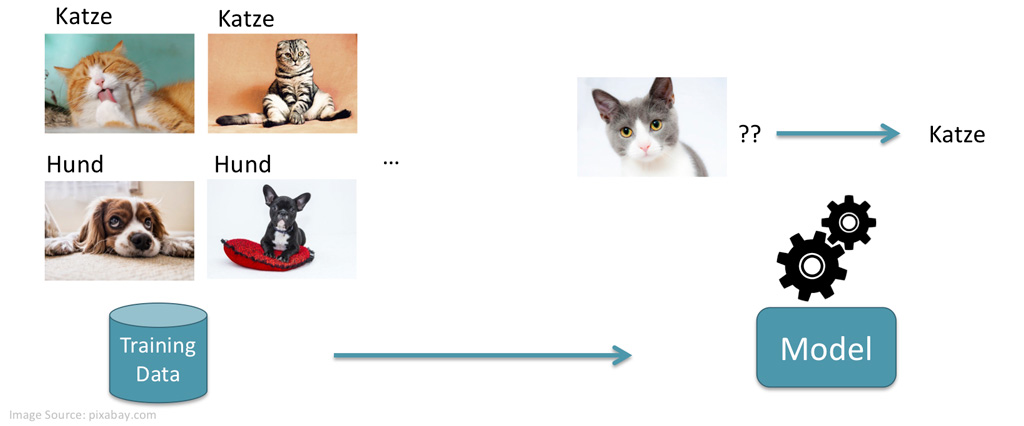
Abbildung 1: Maschinelles Lernen am Beispiel einer Bilderkennungssoftware. Auf der linken Seite Bilder mit bereits gegebenen Labels und auf der rechten Seite ein neues Bild, welches durch das Modell als Katze identifiziert wird.
Abbildung 2: Beispiel von einem kulturellen Bias (basierend auf [4]). Das System erkennt nur eine Frau mit weissem Schleier als Braut, nicht jedoch Bräute aus anderen Kulturen.
Diskriminierung durch künstliche Intelligenz – wie kommt es dazu?
Objektive Entscheide durch Software?
Die Idee, dass Software verwendet wird, um objektivere Entscheide zu treffen, scheint überholt zu sein. Die Fälle von Diskriminierung und unfairen Entscheiden auf Grund maschinellen Lernens (Software mit sog. Künstlicher Intelligenz KI/Artificial Intelligence AI) häufen sich. Forschende in den USA konnten zeigen, dass über Jahre ein Analyseprogramm zur Risikoberechnung für Straftäterinnen und Straftäter verwendet wurde, welches die afroamerikanische Bevölkerung benachteiligt [1]. Bei einer grossen Firma aus der Tech Branche wurde nachgewiesen, dass die Software, welche das Einstellungsverfahren neuer Mitarbeitenden erleichtern sollte, unfair gegenüber Frauen war [2]. Es konnte auch gezeigt werden, dass gesellschaftliche Stereotypen tief in den gängigen Tools zur automatischen Übersetzung verankert sind [3]. Doch wie kann es passieren, dass eine solche Software diskriminiert?
Maschinelles Lernen – eine kurze Einführung
Um das besser zu verstehen, schauen wir uns zunächst einmal an, wie maschinelles Lernen überhaupt funktioniert. Dazu schauen wir uns eine Software an, die Bilder von Katzen und Hunden automatisch erkennen soll. Damit eine Software mit maschinellem Lernen gebaut werden kann, werden zunächst sog. Trainingsdaten benötigt. Trainingsdaten sind in diesem Fall eine Sammlung von Fotos von Hunden und Katzen, welche jeweils mit einem Label versehen sind. Bilder, auf welchen eine Katze zu sehen ist, haben das Label Katze, und analog für die Bilder mit Hunden. Diese Trainingsdaten sind in unserem Beispiel Bilder mit einem Label, können in anderen Programmen aber auch ganz unterschiedliche Formate haben. Basierend auf diesen Trainingsdaten soll die Software die Informationen lernen, welche sie benötigt, um die gewünschten Entscheide zu treffen. In diesem Beispiel soll die Software lernen, wie eine Katze und ein Hund aussehen und wie diese unterschieden werden können. Nach der Trainingsphase auf den Trainingsdaten erhalten wir ein Modell, welches es der Software in unserem Beispiel erlaubt, bei einem gegebenen Bild zu entscheiden, ob es sich um einen Hund oder eine Katze handelt. Abbildung 1 visualisiert diesen Prozess.
Die Auswahl der Trainingsdaten entscheidet also, auf was für einer Basis die Software ihre Entscheidungen trifft. Das gesamte Wissen, welches die Software kennt, sozusagen ihr gesamtes Weltbild, kommt aus diesem Datensatz. Dies zeigt, wie relevant die Ausgestaltung dieser Trainingsdaten ist.
Wie Bias entsteht
Es ist eine herausfordernde Aufgabe, geeignete Trainingsdaten zusammenzustellen. Wir wollen nun beispielsweise eine Software trainieren, welche erkennen kann, ob auf einem Foto eine Braut zu sehen ist. Selbst wenn wir versuchen, eine möglichst ausgewogene Sammlung von Trainingsdaten zu erstellen, mit Bräuten mit verschiedenen Haut- und Haarfarben, so kann es dennoch zu einem Bias kommen. Beispielsweise dann, wenn in der Datensammlung nur Bräute mit dem traditionellen weissen Schleier, wie er häufig in der westlichen Welt verwendet wird, zu finden sind. Eine Braut aus einem anderen Kulturkreis würde mit dieser Software nun nicht erkannt werde, da sie im Weltbild der Software nicht existiert. Dieses Beispiel eines kulturellen Bias wird in Abbildung 2 dargestellt.
Eine wichtige Ursache von diskriminierender Software sind die Trainingsdaten. Ein weiteres Beispiel dafür ist Wikipedia. Oftmals werden die Daten aus Wikipedia verwendet, um Software im Bereich der automatischen Verarbeitung von menschlicher Sprache (sog. Natural Language Processing NLP) zu entwickeln. Es konnte jedoch gezeigt werden, dass die Inhalte von Wikipedia einen Bias enthalten. Studien [5] [6] haben gezeigt, dass eine grosse Mehrheit der Biografien Männer beschreibt. Frauen sind dadurch in diesem Datensatz weniger sichtbar. Ausserdem wurde festgestellt, dass die Art und Weise, wie Frauen und Männer beschrieben werden, unterschiedlich ist: es wurde in diesen Auswertungen festgestellt, dass Frauen oft auf Grund ihrer romantischen Beziehungen oder familiären Situation beschrieben wurden, während bei Männern andere Themen im Vordergrund standen. Ein System, welches auf diesen Texten trainiert wird, lernt auch den darin enthaltenen Bias.
Kommen wir nun noch einmal zurück zum Beispiel aus der Tech Branche, wo das Recruiting Tool unfair gegenüber Frauen war [2]. Auch hier waren die Trainingsdaten das Problem. Die eingehenden Bewerbungen wurden automatisiert bewertet, um die Auswahl der Top-Kandidatinnen und -kandidaten effizienter zu gestalten. Die Software wurde trainiert, indem sie die Lebensläufe der letzten 10 Jahre analysierte. Auf Grund einer existierenden Männer-Dominanz in technischen Bereichen, welche sich auch in den Trainingsdaten zeigte, lernte die Software, dass Männer zu bevorzugen seien, was zu einem unfairen Verhalten gegenüber Bewerberinnen führte.
Risiken minimieren
Die Auswahl geeigneter Trainingsdaten ist daher ein essenzieller Punkt für eine faire Software. Zur Verhinderung von Diskriminierung müssen diese daher sorgfältig ausgewählt und regelmässig überprüft werden. Eine einheitliche Lösung für dieses Problem ist sich aus verschiedenen Gründen sehr komplex: die Definition von Fairness ist nicht einheitlich, und kann durchaus für verschiedene Personengruppen anders sein. Eine Vielzahl an Technologien, Einsatzgebieten und potentiellen Arten der Diskriminierung erschweren das Problem weiter. Während die Forschung untersucht, wie der Bias in Trainingsdaten messbar gemacht und behoben werden kann, diskutieren Politik und Gesellschaft über mögliche Regulationen und deren Umsetzung.
Währenddessen fehlen in den Unternehmen oftmals noch Standardprozesse zur Minimierung der Risiken durch Diskriminierung von künstlicher Intelligenz, welche sowohl nötig sind, wenn solche Software entwickelt wird, aber auch, wenn sie eingesetzt wird. Angegangen werden kann dies momentan durch ein entsprechendes Bewusstsein für die Problematik, welches es erlaubt, die richtigen Fragen zu stellen. Daneben benötigt es die entsprechenden Fachkenntnisse, welche die Umsetzung eines spezifischen Risiko Managements und der daraus resultierenden neuen Prozesse zu etablieren. Solche vorkehrenden Massnahmen reduzieren das Risiko, durch die Entwicklung oder den Einsatz von Software mit künstlicher Intelligenz zu diskriminieren.
Referenzen:
[1] Larson, J., Mattu, S., Kirchner, L. & Angwin, J., 2016. How we analyzed the COMPAS recidivism algorithm. ProPublica, May.
[2] Jeffrey, D., 2018. Amazon scraps secret AI recruiting tool that showed bias against women, San Fransico, CA: Reuters.
[3] https://www.republik.ch/2021/04/19/sie-ist-huebsch-er-ist-stark-er-ist-lehrer-sie-ist-kindergaertnerin
[4] Zou, J. & Schiebinger, L., 2018. AI can be sexist and racist—it’s time to make it fair, s.l.: Nature Publishing Group.
[5] Jadidi, M., Strohmaier, M., Wagner, C. & Garcia, D., 2015. It’s a man’s Wikipedia? Assessing gender inequality in an online encyclopedia. s.l., s.n.
[6] Wagner, C., Graells-Garrido, E., Garcia, D. & Menczer, F., 2016. Women through the glass ceiling: gender asymmetries in Wikipedia. EPJ Data Science, 5(1).
Prof. Dr. Mascha Kurpicz-Briki

Professorin für Data Engineering am Institute for Data Applications and Security (IDAS) der Berner Fachhochschule.
Sie beschäftigt sich in ihrer Forschung unter anderem mit dem Thema Fairness in künstlicher Intelligenz und der Digitalisierung von sozialen und gesellschaftlichen Herausforderungen. Insbesondere setzt sie sich damit auseinander, wie digitale Ethik in Unternehmen konkret umgesetzt werden kann.
Gut zu wissen
Was ist ein Bias?
Im Rahmen der digitalen Ethik meinen wir mit Bias eine Unausgewogenheit gegen eine bestimmte Gruppe. Ein Bias liegt beispielsweise vor, wenn eine Software systematisch Frauen und Männer anders behandelt. Oftmals sind dieselben Gruppen betroffen, welche bereits in der analogen Welt diskriminiert werden, da die Vorurteile durch Software reflektiert oder sogar verstärkt werden.